Predicting Visitor-to-Customer Conversion for an Online Store via Supervised Machine Learning- Part 1: Introduction to Business Case and Exploratory Data Analysis
In this two part series, I will write about my experience working on a Kaggle Data Challenge (Here’s the Link) as a part of a graduate course on Statistical Learning that I took at the University of Waterloo as a Masters Student in Statistics.
In the first part, I will talk about the following two topics:
- Business Case behind this Data Science problem
- Exploratory Data Analysis
So, let’s dive in straight into the problem:
- Business Case:
The owner of an online jewellery shop wants to figure out a way to increase her revenues. In particular, she wants to accurately predict whether a visitor to her website will end up purchasing a jewellery product.
At a surface level, this looks like a simple issue. Let’s say she gets 1000 visitors to her website on an average per week and 10 of them buy a product. So all she has to do is analyze web-data about 10 these people and generate targeted advertisements to get them buy more in the future.
Let’s stop and think about the intricacies of this issue. These people have already purchased her product. So they are likely to make purchases in the future too. Out of the remaining 990, are there customers similar to these customers who left just short of making a purchase ? If so, what features underlie this similarity ? Where are the customers located, when do they make the purchase, can the non-buyers be nudged to make a purchase if we come to know that some of them spent a while on pages where a discount was running, how many of the people who did not make a purchase this week are existing customers and how many of them are new visitors ?
As we see, the task of increasing the revenue of an online store through predictive analytics is far from trivial. There are many variables and in such a multi-dimensional setting, we can leverage the power of Machine Learning to improve the accuracy of customer prediction and uncover insights from the patterns that we can then leverage to achieve our objective of increasing sales.
2. Exploratory Data Analysis
Imbalanced Dataset
The training and the test datasets can be found here on my GitHub page of the project.
The training and the test datasets consist of 8630 and 3700 visitor entries respectively. The predictor variable Revenue is set to1 for visitors who turned customers and 0 otherwise.
The dataset is highly imbalanced i.e. out of the 8630 visitors in the training dataset, only 1335 turned customers, i.e. a conversion rate of 15.4%.
This is important to note because we want to make sure that our prediction algorithm does not err on the side of the majority class and simply predict every entry as a non-customer. So we must choose the right metric to evaluate the results of our predictive algorithm. An example will make this clear:
Let’s say that we have an algorithm that simply labels every entry as belonging to the majority class. In our case, out of every 100 entries, 85 will belong to the majority class (Non-Revenue ) and therefore, the algorithm that simply labels each entry as non-revenue will achieve an accuracy of 85%. The downside however is that it has a 0% accuracy over entries that belong to the minority class as it will classify every Revenue entry as Non-Revenue.
So Accuracy is not the right metric here. Instead, we choose a metric that captures how well the algorithm classifies the minority class. The ROC AUC score is one such metric. ROC AUC stands for Receiver Operating Curve — Area Under Curve. The ROC AUC score ranges between 0 and 1 and a high value signifies that the model has high skill in separating the positive and the negative examples. It is a commonly used metric to evaluate the performance of models especially in cases of imbalanced datasets. A good explantion of the underlying theory and intuition can be found here
Data Attributes
The dataset has 17 predictor attributes that are either numerical ( continuous and discrete) and categorical, a customer ID and the revenue output variable that takes either 0 or 1.
I have created a word document here that has a brief description of each of these attributes.
Missing Values
I sorted the training dataset (online_jewellery_shop_train.xlsx) in Excel to see if some entries had some attributes that were missing. There were 8 entries that had 8 missing attributes. As these 8 entries represent less than 0.1% of the training dataset, I removed them from the dataset. Similarly, the test dataset had 6 entries that did not have these 8 attributes and I removed them too. I approximated the visitor to customer conversion probability for these missing test set entries by assigning the average value of the predicted probabililty of the whole test class to each of them. While this is an approximation, given that the missing entries are very few (~0.1%) and the pattern of missing attributes is consistent, I felt this would be an acceptable thing to do in this case. If the number of entries with missing values were significant, say 5–10% of the dataset, then this strategy of removing missing values could lead to a loss of valuable information. An alternative strategy, such as imputing missing values would be needed in that case.
The missing attributes of the training and the test datasets are shown in the tables below:


The training and the test datasets after removing the entries that have missing attributes can be found here (input_training_data.csv and input_test_data.csv).
Trends from Exploratory Data Analysis:
I present some trends that I observed from the EDA that I performed on the Training Data. The underlying theme behind my EDA is the following:
For each categorical attribute, I have plotted the percentage of Revenue (0) and Non-Revenue (1) visitors and compared that to the average value of Revenue visitors, i.e ~15%. By doing so, I hope to check if there are some attributes whose specific values result in disproportionately high or low revenue generating visitors. I have used the terms revenue visitors/revenue generating visitors and customers interchangeably.
For example, on plotting the percentage of revenue generating visitors vs the number of jewellery pages they visit, it is clear that those visitors who visit more than 20 pages have a signigicantly higher conversion rate than visitors who visit less than 20 pages.
This suggests that if the website is made appealing for people to stay and browse jewellery pages, people might buy more. This is a correlation and might not mean causation, i.e. those visitors who eventually buy might be spending more time on jewellery pages. However, one can do an experimental design and test the hypothesis that appealing webpages make people stay more and eventually buy more as well.

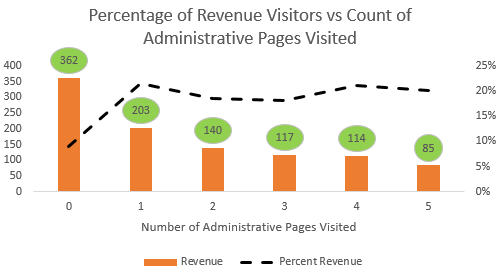
For example, when I plotted the customers as per the number of administrative pages that they visited, I observed that there is no particular trend in terms of the percentage of customers (Revenue=1) and the number of administrative pages that they have browsed except the fact that out of those visitors who do not browse any adminstrative page (3994 of them), only 9% (362) made a purchase. So prima facie, the number of administrative pages seems to be a non-significant factor for revenue generation except for this tid-bit of observation.
I have shared the results of my exploratory data analysis here
Here’s the summary of my EDA findings:
- Page Values: There is a strong positive correlation between the number of jewellery shop pages visited and the conversion rate. People who visit more than 20 pages have an especially higher conversion rate (>70%)as compared to the people who visit 20 or less pages (~10%). This suggests that if the website is made appealing for people to stay and browse jewellery pages, people might buy more. This is a correlation and might not mean causation, i.e. those visitors who eventually buy might be visiting more jewellery pages. However, one can do an experimental design and test the hypothesis that appealing webpages make people stay more and eventually buy more as well.
- Exit Rate: There is a strong negative correlation between the Exit Rate and the conversion rate. Exit rates of 0.02 and above are associated with a below average rate of conversion.
- Bounce Rate: There is a strong negative correlation between the Bounce Rate and the conversion rate. Bounce rates of 0.01 and above are associated with a below average rate of conversion.
- Time spent on Product Related pages: There is a strong positive correlation between the time visitors spent on Product Related pages and the conversion rate. People who spent beween 3200–6400 units of time on product related pages had a conversion rate of ~30%. This insight can help in boosting sales by for example, installing a time tracker on the website and as soon as people exceed a threshold of time spent on product related pages, they can be offered a discount to prompt them to buy a product.
- Time spent on Informational pages: There is a weak positive correlation between the time visitors spent on Informational pages and the conversion rate. While there is clearly a jump at 130 units, i.e. people spending over 130 units have at least 25% conversion rate as compared to 15% for those spending less than 130 units of time, those who spend 520–650 units have a conversion rate of only 27%.
- Time spent on Administrative pages: Similar to the case of informational pages, there is a weak positive correlation between the time visitors spent on Adminstrative pages and the conversion rate.
- Number of Product Related Pages visited: There is a strong positive correlation between the number of Product Related pages visited by people and the conversion rate. It is quite likely that there might be a strong correlation between this variable and the time spent on product related pages. I have not checked for such correlations in this data challenge but will address this issue in a separate post.
- Number of Administrative Pages visited: Overall, there does not seem to be a correlation but those visitors who do not visit administrative pages at all buy at a significantly lower rate (9%)than those who visit one or more pages (20%). Again, this variable could be strongly correlated with the time spent on adminstrative pages.
- Number of Informational Pages visited: The trend seems to be quite similar to the time spent on informational pages. So these two variables could be correlated.
- Closeness to a special day: It might seem counter intuitive, but closeness of the day of visit to a special day results in a lower conversion rate. This of course depends on how we define the degree of closeness but if 0 means that the day of visit is far from the special day and 1 means that the day of visit is on the special day, then there is clear a negative correlation.
- Month of visit: November seems to be the month having the highest conversion rate (26%). This store can use this observation to sell more during this month, i.e. try channeling more traffic to the website during November and see whether it results in even higher sales.
- Weekend: Weekends result in higher conversion rates as compared to weekdays, 17% vs 15%.
- Visitor Type: A new visitor has a significantly higher conversion rate (25%) than a returning visitor (15%). This means that if a new visitor is coming to the website, one can leverage the novelty of experience to make a sale. This can be opportunistic but can be acted upon if the site experience is good enough for a sizeable majority of the new visitors to return.
- Traffic Type: Traffic Type 2 results in the maximum number of conversions (587) and has a relatively high rate as well (20%). The IT team can investigate why the highest number of revenue generators belong to this type and if this variable is alterable, then can other people also be converted to traffic of this type ?
- Region: This does have any effect on conversion rates. So region based marketing might not be helpful for this store. However, by far the maximum number of revenue generating visitors are from Region 1 (549). So the marketing team must be careful to make sure that they guard their position in thos region from competition.
- Browser: Most buyers seem to use Browser 2 but the type of browser does not seem to have only a weak correlation with conversion rates.
- Operating System: While Operating Systems 2 and 1account for most revenue generating visitors, there is no correlation of conversion rates with this variable either.
So the key business insights that I got from the EDA are the following:
A. Focus on Web-Design: Investing in making the Website more appealing and user friendly can potentially result in higher sales: There is a strong positive correlation between variables such as Page Value, Number of Product Pages visited etc and the conversion rate. So, there seems to be a business case for investing in increasing the retentive capacity of the website. One can confirm this hypothesis by designing, running and analyzing experiments.
B. Fix technical issues of the website: A low Exit Rate and Bounce Rate have high conversion rates. So reducing these two rates are also likely to result in a higher conversion rates.
C. Give special care to new visitors : New visitors to the website have a higher conversion rates than existing visitors. So, if a new visitor is coming to the website, the marketing team can offer discounts / special deals to convert these first time visitors to revenue generating visitors.
D. Certain months result in higher conversion rates: November seems to be the golden month. So, the marketing budget can allocate a higher portion of spending to the weeks leading to November and the month of November itself.
E. Special Days: Contrary to what one might think, conversion rates on special days are lower than normal days.
That’s it for Part 1! I Hope you found something here that you can apply in your work.
In Part 2 (see here), I will be covering Data Preprocessing and Implementing Supervised Classfification Algorithms ( Random Tree and XGBoost).