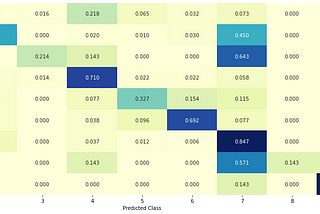
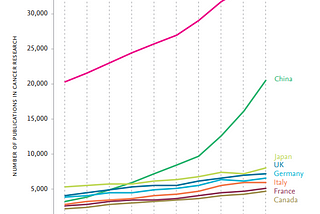
Bharat Sethuraman SharmaninTowards Data ScienceDistributed Biomedical Text Mining using PySpark for Classification of Cancer Gene Mutations…5 min read·May 8, 2021--1--1
Bharat Sethuraman SharmaninTowards Data ScienceDistributed Biomedical Text Mining using PySpark for Classification of Cancer Gene Mutations…12 min read·May 8, 2021----
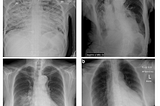
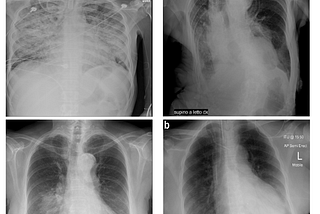
Bharat Sethuraman SharmaninTowards Data ScienceHigh-Accuracy Covid 19 Prediction from Chest X-Ray Images using Pre-Trained Convolutional Neural…In this post, I will share my experience of developing a Convolutional Neural Network algorithm to predict Covid-19 from chest X-Ray…11 min read·Feb 21, 2021--2--2
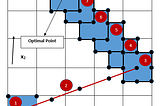
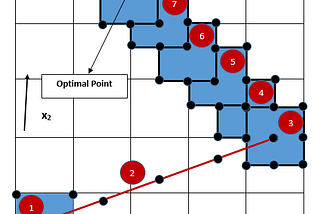
Bharat Sethuraman SharmaninTowards Data ScienceAn Experimental Design Approach to Solve a Multivariate Optimization ProblemFinding the optimal value when the design function is unknown12 min read·Jan 16, 2021--1--1
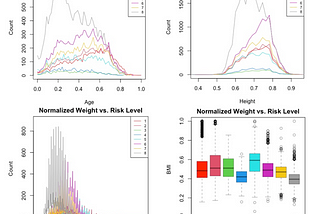
Bharat Sethuraman SharmaninTowards Data ScienceLife Insurance Risk Prediction using Machine Learning Algorithms- Part II: Algorithms and ResultsAlgorithmic Risk Prediction of Life Insurance Applications through supervised learning algorithms — By Bharat , Dylan , Leonie and Mingdao…5 min read·Jan 10, 2021----
Bharat Sethuraman SharmaninTowards Data ScienceLife Insurance Risk Prediction using Machine Learning Algorithms- Part I: Data Pre-Processing and…Algorithmic Risk Prediction of Life Insurance Applications through supervised learning algorithms — By Bharat , Dylan , Leonie and Mingdao…12 min read·Jan 10, 2021----
Bharat Sethuraman SharmaninThe StartupPredicting Visitor-to-Customer Conversion for an Online Store via Supervised Machine Learning…In Part 1(you can read it here), I discussed the Business Case for Predicting Visitor-to-Customer Conversion for an Online Store and…7 min read·Oct 28, 2020--1--1
Bharat Sethuraman SharmaninThe StartupPredicting Visitor-to-Customer Conversion for an Online Store via Supervised Machine Learning…In this two part series, I will write about my experience working on a Kaggle Data Challenge (Here’s the Link) as a part of a graduate…10 min read·Oct 27, 2020----